In an earlier post discussing the history of Git, we discussed how most version control systems stored only the changes that were made from one version to next. When they had to recreate a particular version of a file, they merely added all the patches from the first version until the desired version. This is commonly called as delta-based version control.
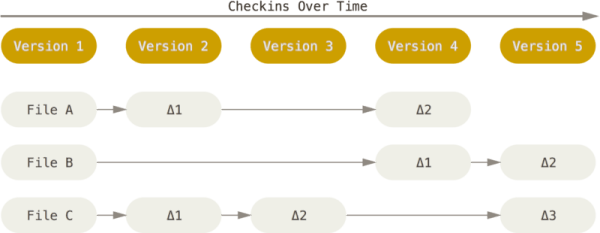
Storing data as changes. Courtesy
However, Git differs from them in the way it stores the versions. It does not store the versions in the form of changes/patches.
Git - Storing data like a series of snapshots
With each Git commit, Git creates a snapshot of the current state of the repository and stores it (technically, it just stores a reference to the snapshot). So, in a way, Git stores multiple copies of your project - each copy pointing to a version.
What is the benefit of storing the versions as snapshots?
One of the major benefits of storing the version data this way is the ability to create branches very easily. We will cover this in more detail when we discuss Git branching in a later post.
But, isn’t this wasting a lot of storage?
In a way, yes. But it is trading off storage (which is cheaper) for ease of use and better collaboration abilities.
Also, in order to be efficient if a file has not changed in a commit, Git just stores a link to the previous snapshot of the file.
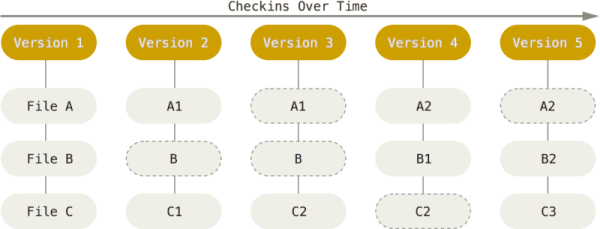
Storing data as snapshots. Courtesy